You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: src/content/docs/packages/semble/benchmarks.mdx
+64-29Lines changed: 64 additions & 29 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -16,9 +16,11 @@ We benchmark quality and speed across all methods on ~1,250 queries over 63 repo
16
16
| CodeRankEmbed | 0.765 | 57 s | 16 ms |
17
17
| ColGREP | 0.693 | 5.8 s | 124 ms |
18
18
| BM25 | 0.673 | 263 ms | 0.02 ms |
19
-
| ripgrep | 0.126 | — | 12 ms |
19
+
| grepai | 0.561 | 35 s | 48 ms |
20
+
| probe | 0.387 | - | 207 ms |
21
+
| ripgrep | 0.126 | - | 12 ms |
20
22
21
-
Semble achieves 99% of the retrieval quality of the 137M-parameter CodeRankEmbed Hybrid, while indexing **218× faster** and answering queries **11× faster** — entirely on CPU.
23
+
Semble achieves 99% of the retrieval quality of the 137M-parameter CodeRankEmbed Hybrid, while indexing **218× faster** and answering queries **11× faster**, entirely on CPU.
22
24
23
25
The charts below plot latency against NDCG@10. Marker size reflects model parameter count.
24
26
@@ -28,32 +30,63 @@ The charts below plot latency against NDCG@10. Marker size reflects model parame
28
30
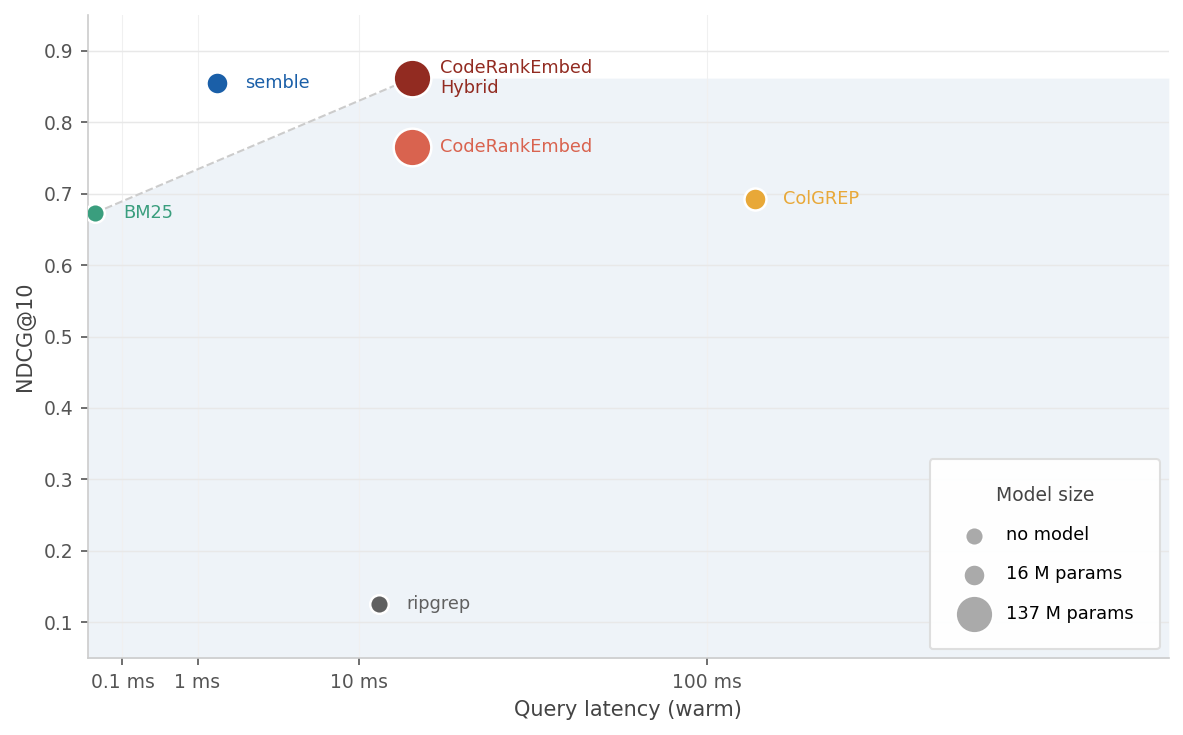
29
31
*Query latency on a warm index vs NDCG@10*
30
32
33
+
## Token Efficiency
34
+
35
+
Coding agents (Claude Code, OpenCode, etc.) typically find code by running `grep` on keywords and reading the matched files. We model that workflow and compare it against semble's chunk retrieval across our full benchmark of 1,251 queries.
36
+
37
+
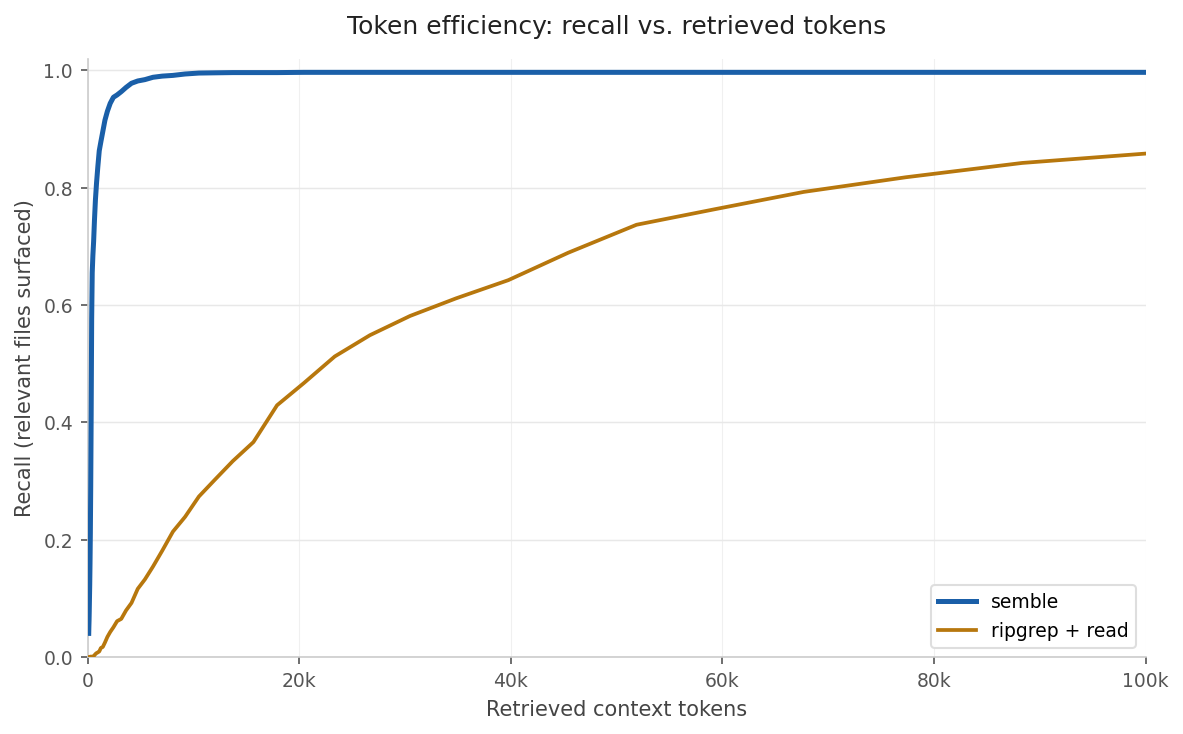
38
+
39
+
### Expected tokens per query
40
+
41
+
For each query: tokens consumed at first relevant hit, or 32k if the method never finds anything. Averaged across all 1,251 queries.
42
+
43
+
| Method | Expected tokens | Savings |
44
+
|--------|----------------:|--------:|
45
+
| ripgrep + read file | 45,692 | baseline |
46
+
|**semble**|**566**|**98% fewer**|
47
+
48
+
### Recall at fixed token budgets
49
+
50
+
A relevant file is "covered" once any retrieved unit comes from it.
Semble returns the top-50 ranked chunks. `ripgrep+read` splits the query into keywords (dropping stopwords and short words), runs `rg --fixed-strings --ignore-case` for each keyword, then reads matched files in full ranked by how many distinct keywords they contain. Both methods search the same set of file types and ignored directories. Tokens are counted with `cl100k_base` via `tiktoken`. A relevant file is "covered" once any retrieved unit overlaps its annotated span.
61
+
62
+
</details>
63
+
31
64
## By Language
32
65
33
66
NDCG@10 per language. Best score per row is bolded.
-**[ripgrep](https://github.com/BurntSushi/ripgrep)**: fast regex search, included as a raw keyword-match baseline.
126
+
-**[probe](https://github.com/buger/probe)**: BM25 keyword ranking backed by tree-sitter parse trees. No persistent index; scans on the fly.
127
+
-**[ColGREP](https://github.com/lightonai/next-plaid/tree/main/colgrep)**: late-interaction code retrieval with the LateOn-Code-edge model.
128
+
-**[grepai](https://github.com/nicholasgasior/grepai)**: semantic search using [nomic-embed-text](https://huggingface.co/nomic-ai/nomic-embed-text-v1) (137M params) via a local Ollama daemon.
129
+
-**[CodeRankEmbed](https://huggingface.co/nomic-ai/CodeRankEmbed)**: 137M-param transformer embedding model. *CRE Hybrid* fuses its dense scores with BM25.
Copy file name to clipboardExpand all lines: src/content/docs/packages/semble/introduction.mdx
+6-6Lines changed: 6 additions & 6 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -5,7 +5,7 @@ sidebar:
5
5
icon: open-book
6
6
---
7
7
8
-
[Semble](https://github.com/MinishLab/semble) is a code search library built for agents. It returns the exact code snippets they need instantly, cutting both token usage and waiting time on every step. Indexing and searching a full codebase end-to-end takes under a second, with ~200x faster indexing and ~10x faster queries than a code-specialized transformer, at 99% of its retrieval quality (see [benchmarks](/packages/semble/benchmarks/)). Everything runs on CPU with no API keys, GPU, or external services.
8
+
[Semble](https://github.com/MinishLab/semble) is a code search library built for agents. It returns the exact code snippets they need instantly, using ~98% fewer tokens than grep+read and cutting latency on every step. Indexing and searching a full codebase end-to-end takes under a second, with ~200x faster indexing and ~10x faster queries than a code-specialized transformer, at 99% of its retrieval quality (see [benchmarks](/packages/semble/benchmarks/)). Everything runs on CPU with no API keys, GPU, or external services.
9
9
10
10
Run it as an [MCP server](/packages/semble/mcp-server/) and any agent (Claude Code, Cursor, Codex, OpenCode, etc.) gets instant access to any repo, cloned and indexed on demand.
11
11
@@ -60,10 +60,10 @@ Semble splits each file into code-aware chunks using [Chonkie](https://github.co
60
60
61
61
The two score lists are fused with Reciprocal Rank Fusion (RRF) and then reranked with a set of code-aware signals:
62
62
63
-
-**Adaptive weighting** — symbol-like queries (`Foo::bar`, `getUserById`) get more lexical weight; natural-language queries stay balanced.
64
-
-**Definition boosts** — a chunk that defines the queried symbol (`class`, `def`, `func`) ranks above chunks that merely reference it.
65
-
-**Identifier stems** — query tokens are stemmed and matched against identifier stems, so `parse config` boosts chunks containing `parseConfig`, `ConfigParser`, or `config_parser`.
66
-
-**File coherence** — when multiple chunks from the same file match, the file is boosted so the top result reflects broad file-level relevance.
67
-
-**Noise penalties** — test files, `compat`/`legacy` shims, example code, and `.d.ts` stubs are down-ranked so canonical implementations surface first.
63
+
-**Adaptive weighting**: symbol-like queries (`Foo::bar`, `getUserById`) get more lexical weight; natural-language queries stay balanced.
64
+
-**Definition boosts**: a chunk that defines the queried symbol (`class`, `def`, `func`) ranks above chunks that merely reference it.
65
+
-**Identifier stems**: query tokens are stemmed and matched against identifier stems, so `parse config` boosts chunks containing `parseConfig`, `ConfigParser`, or `config_parser`.
66
+
-**File coherence**: when multiple chunks from the same file match, the file is boosted so the top result reflects broad file-level relevance.
67
+
-**Noise penalties**: test files, `compat`/`legacy` shims, example code, and `.d.ts` stubs are down-ranked so canonical implementations surface first.
68
68
69
69
Because the embedding model is static with no transformer forward pass at query time, all of this runs in milliseconds on CPU.
0 commit comments