Architecture Principle: AI systems fail in coordination, not compute. GPUs rarely fail. The storage and network feeding them fail constantly.
This repository contains the diagnostic frameworks and reliability models for maintaining high-performance AI infrastructure and eliminating GPU starvation.
The continuously maintained architectural specification lives here: 👉 https://www.rack2cloud.com/ai-infrastructure-strategy-guide/
AI clusters exhibit non-linear failure patterns. Traditional availability metrics do not model distributed training reliability.
When training stalls or inference latency spikes, the root cause is almost always outside the compute nodes. The failure originates from checkpoint timing, storage IO limits, GPU desynchronization, or network jitter.
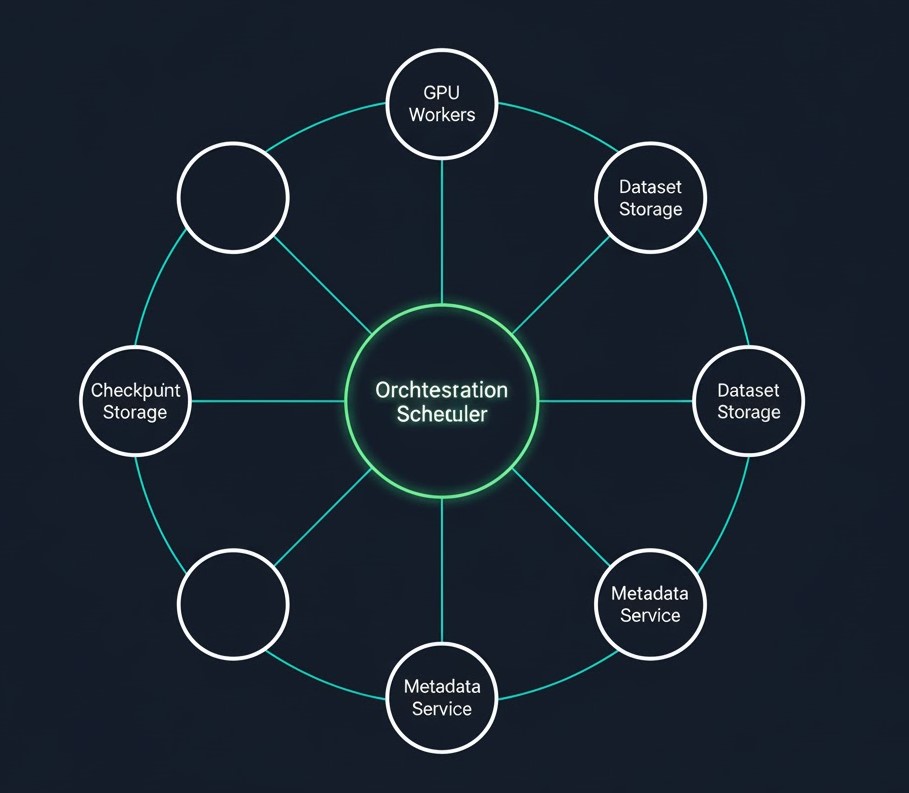
Layers of Dependency:
- Dataset Storage (Cold/Warm)
- Metadata Service
- Checkpoint Storage (Hot)
- GPU Workers
- Orchestration Scheduler
Throughput consistency is vastly more important than peak theoretical bandwidth. Here is how distributed training actually fails, and how to fix it:
| Failure Mode | Symptom / Impact | Architectural Mitigation |
|---|---|---|
| Checkpoint Stalls | GPUs drop to 0% utilization every few hours; Training pauses. | Implement parallel file systems (e.g., WEKA, Lustre) instead of standard NFS for multi-tier caching. |
| Network Jitter / Incast | Multi-node training efficiency drops; Throughput collapses. | Deploy lossless, dedicated RoCEv2 or InfiniBand fabrics with tuned Priority Flow Control (PFC). |
| Node Desync | Gradient corruption; Entire job crashes if one node fails. | Implement fault-tolerant orchestration (like Torch Distributed Elastic) to handle worker scaling without full restarts. |
| API Rate Limiting | Zombie API keys draining LLM token quotas; Inference timeouts. | Deploy an AI-specific API Gateway (Control Plane) for strict token-level throttling. |
- AI Model tuning or hyperparameter guidance
- GPU hardware benchmarking
This is an infrastructure reliability and diagnostic model.
If this framework improved your cluster reliability modeling or helped you identify a bottleneck, please star the repository.
Architectural frameworks maintained by Rack2Cloud.